Augmented Reality is more than Virtual Reality
Light field displays
(This is genuine new material, not yet contained in the book. Any kind of 3D recording and display approaches are relevant to augmented reality, so this belongs here. The concept described works entirely different from usual auto stereoscopic displays. All rights preserved.)
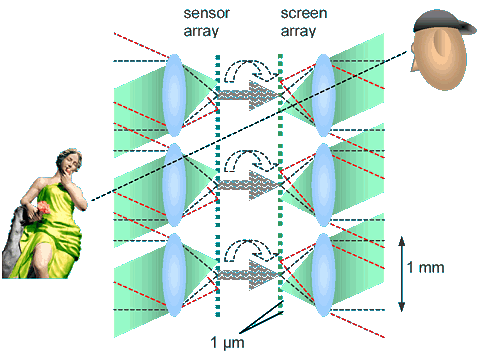
A dense array of micro cameras could record all light beams going through an area in space (e.g. a window that we or the cameras are looking through). They would take up all information about angle, position and intensity of all beams, hence all information to reconstruct them. This is called a light field. As a description of natural views, an alternative to holography.
Each camera converts angle to position on its image sensor.
An equivalent array of micro projectors could reproduce all beams with high accuracy.
Signal transmission could use raw data (this are n^4 pixels!), compressed light field data, or synthetic holographic data.
From the view of fundamental physics, the approach would be conceivable (1mm camera size, 1µm pixel size are in the possible range and well fit for large screens).
Each camera/projector pair here acts like a camera obscura, hence a small hole, and many small holes simply are forming a window !
In practice, one would of course use fewer cameras, fill the perspective gaps by computation, and chose a simpler reproduction approach.The major step towards realistically conceivable light field displays would be concentrating on the horizontal perspective and generating at least the vertical perspective viewer specific only. But let us first look into some fundamentals, before presenting a realistic approach :
Micro lens guide
Projects involving lenticular arrays have usually always been running in circles, literally, trying to achieve a perfect light field representation by nothing but beam shaping. In the real world, it is almost impossible this way to avoid transition effects when viewers change position.
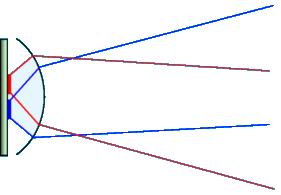
The answer is adaptive displays, dynamically generating user specific beams (and here we are not referring to the many single viewer approaches simply shifting around grids of stereo display stripes).Before getting into this, one has to comprehend, again, that lenses can be described as position to angle converters. For micro lenses of a lenticular array, we can make the following assumptions:
Micro lenses can deliver a very large depth of field. Overlapping beams can be achieved by slight blurring or defocus. Optical perfection is not necessary and stripe positioning is absolutely uncritical if adaptive display techniques (calibration and user tracking) are employed.
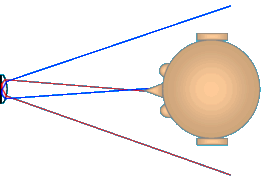
A micro lens projection assembly is simply the opposite of a camera with a tiny lens: As anybody knows, a dirt cheap camera with only a millimeter wide lens can record a HD picture, hence have the necessary angular resolution. Vice versa, the micro projector can also resolve hundreds of different angles at ease.
Simple 2-stripe assembly for a stereo parallax display Far field of stereo parallax display Multi stripe assembly of a light field display and light beam bundle drawing separate pictures to a viewer's separate eyes Maximum angular resolution (approx.): a/f = /d Example: a=0.5mm, f=3m,
A new idea: dynamic beam shaping
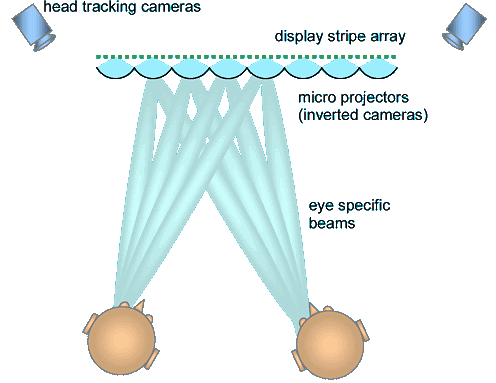
Here we have such a special lenticular light field display, the inverse of a camera array.
We use display and lens stripes. It is horizontal stereo only, but vertical perspective (or even the entire picture), can also be viewer specific.
Each lens forms a micro projector (inverted camera) with extreme depth of field. Stripe position is converted into angle. High angular resolution is possible.
In viewer adaptive mode, only stripes corresponding to an actual user's eye would be activated, and tolerances could be compensated: The display would be pre-calibrated once before use, by displaying test patterns and analyzing the signals from the tracking cameras. Hence, high precision is not necessary here, neither concerning lens geometry nor stripe positioning !If the viewer moves, the next stripe takes over, at this time showing the same image content as the former one. Hence, here we have no switching of perspectives, with good calibration also no brightness fluctuations between stripes. Nevertheless, the perspective generated will smoothly follow the user's movements all the time (even while only slightly moving within the width of a single stripe).
Hence, here we have a light field display without the switching effects and with an extremely reduced complexity at the same time.
Such a display is nowadays achievable, it can be manufactured as a high resolution OLED display, in future maybe even as a wallpaper (roll-to-roll printing and lens stripe engraving) display.
Hence, this will be quite a cheap approach, and this is very important, as there already is no big market for expensive displays any more, and even the less so in the future, when they will have to compete with display glasses.
It can't be pointed out strong enough how entirely different this is from the numerous auto stereoscopic approaches that have been unsuccessfully resuscitated during the last decades over and over again. While these were trying to deliver more and more perspectives simultane-ously, boosting complexity and complications, causing switching effects when viewers moved from one perspective to another, here we generate a specific perspective for a specific user at a time, the perspective changes when the user moves, even if he is still on the area of the same display stripe, it even changes when he moves vertically, generating a perfect 3D impression in all directions, and when he has moved far enough in the horizontal direction to enter the area covered by the next display stripe, this stripe will show exactly the same perspective during the transition, delivering a smooth and seamless takeover.
The only disadvantage of the approach: perspectives for one viewer may sometimes interfere with others. But only if two viewers are at the same horizontal position, not so likely in typical TV viewing situations.
The major advantages: 'only' about 10 times the active pixel count of normal displays are required, only perspectives for really present viewers have to be generated and displayed. There is also a huge energy saving, as only display stripes for actual viewers are to be activated, pointing the light exclusively in their directions.This idea was first explained to a larger academic audience in an invited talk at Weimar University, October 16, 2007, and was concurrently added to this website. Here are the original pages from the lecture. The beam shaping illustration that had been quickly done for the lecture was improved a bit when the 3rd edition of The End of Hardware was written.
Light field encoding
While finding a suitable compression method for light fields seems to be very difficult at a first glance, retreating just to the encoding of multiple camera views could simplify things alot. Let us consider this a bit further.
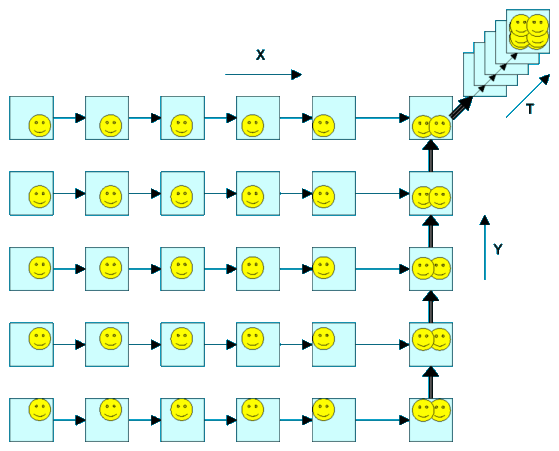
Pictures from neighboring cameras show similarities identical to those in a time sequence from a single camera move (it's obvious, these pictures could have been recorded by a single camera moving sideways on a rail). Classical motion encoding (MPEG) can therefore encode such a sequence at ease.
Encoded line picture sequences could be treated the same way again, compressing the columns, with the sole complication that some meta data has to be treated as well. Finally, the entire compound including all meta data, could be encoded exploiting similarities over the time axis (T).The method would require no "intelligent" image processing, nor would it deliver any hint about depth. It could however be a feasible approach to encode all camera pictures for later retrieval. Intermediate perspectives would be derived at playback time only, then requiring sort of "intelligence" of course. Feb.24,2008
home more notes order
Copyright © 2006-2011 Rolf R. Hainich; all materials on this website are copyrighted.
Disclaimer: All proprietary names and product names mentioned are trademarks or registered trademarks of their respective owners. We do not imply that any of the technologies or ideas described or mentioned herein are free of patent or other rights of ourselves or others. We do also not take any responsibility or guarantee for the correctness or legal status of any information in this book or this website or any documents or links mentioned herein and do not encourage or recommend any use of it. You may use the information presented herein at your own risk and responsibility only. To the best of our knowledge and belief no trademark or copyright infringement exists in these materials. In the fiction part of the book, the sketches, and anything printed in special typefaces, names, companies, cities, and countries are used fictitiously for the purpose of illustrating examples, and any resemblance to actual persons, living or dead, organizations, business establishments, events, or locales is entirely coincidental. If you have any questions or objections, please contact us immediately. "We" in all above terms comprises the publisher as well as the author. If you intend to use any of the ideas mentioned in the book or this website, please do your own research and patent research and contact the author.